Attention
This document is no longer being updated. For the most recent documentation, including the latest release notes for version 6, please refer to Documentation Version 7
In this part of the documentation, we will walk you step by step through all modules and dialogues in the Datavault Builder GUI.
Staging
The staging area is used to connect the Datavault Builder to sources, such as databases, files or even REST-Apis.
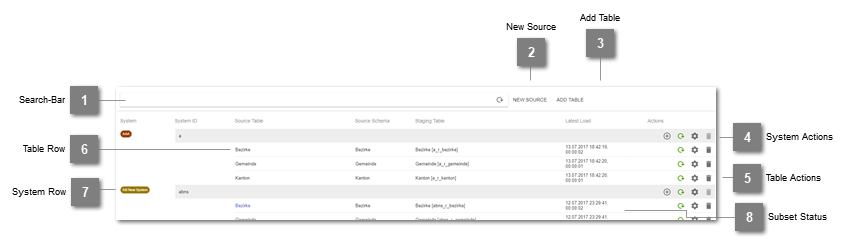
- Search-Bar
Allows to filter the Staging-List for System Name, System ID or Staging Table.
- New Source
Allows to define a new source connection by opening up the New Source Dialogue.
- Add Table
Opens up the Add Table Dialogue to add a new staging table for a previously defined source system.
- System Actions

Plus: Opens up the Add Table Dialogue with a prefilled source system.
Circled arrow: Initiates a full load of all the defined staging tables of the system. Color/Hovering indicates loading status.
Screw nut: Opens up the Edit Source Dialogue, which allows to change all editable properties of the New Source Dialogue.
Trash bin: Removes the Source System. This action is only available if no dependent staging tables or jobs are defined.
- Table Actions

Circled arrow: Initiates a full load of the specific staging table. Color/Hovering indicates loading status. While loading, the button can be used for cancelling.
Screw nut: Opens up the Edit Staging Table Dialogue, which allows to change all editable properties of the Add Table Dialogue.
Trash bin: Removes the Staging Table. This action is only available if no dependent data vault loads are defined.
- Table Row
Lists the Source Table, Source Schema, Staging Table and last succeeded load date and duration. Clicking onto the Source Table* or Staging Table opens up the Data Preview. (*if supported)
- System Row
Lists the System Name and System ID.
- Subset Status

Load definition has/had a General Subset Where Clause.

Load definition has/had Delta load Subset Where Clause.
- Coloring:
black: no load has yet been executed but a subset where clause is defined
green: a load has been executed with the current subset where clause definition
orange: a load has been executed but in the meantime the subset definition has changed
red: a load has been executed but in the meantime the subset definition has been removed
Connecting a new source
- Definition
A source is a connection to a data origin. This origin can be either a database, files or even a webservice.
- Steps
Navigate to the Staging Module.
Click onto
New Source.Fill out the Base-Tab.
Fill out the Connection-Tab.
Confirm the creation on the Review-Tab.
Base
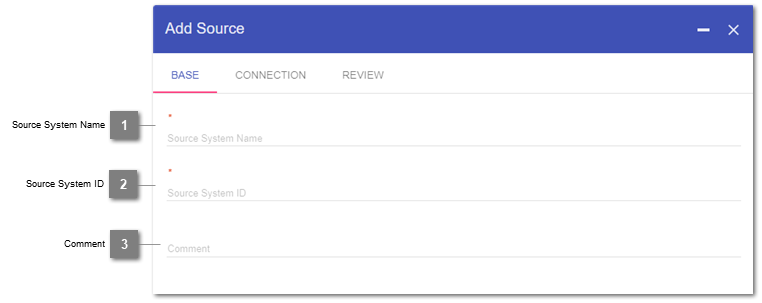
- Source System Name
Declaration of the Name to be displayed for the System. Mandatory; Editable.
- Source System ID
Declaration of the System ID, which is used for the naming of the technical implementation (such as tables, views, …) related with that system on the database. Mandatory.
- Comment
Individual notes about the system. Will as well appear in the documentation. Editable.
Connection
In this step, the connection properties are declared. The Datavault Builder can connect to any source providing a JDBC-Driver. You can add you own specific drivers.
Note
Please directly contact us, if you are missing a certain default driver
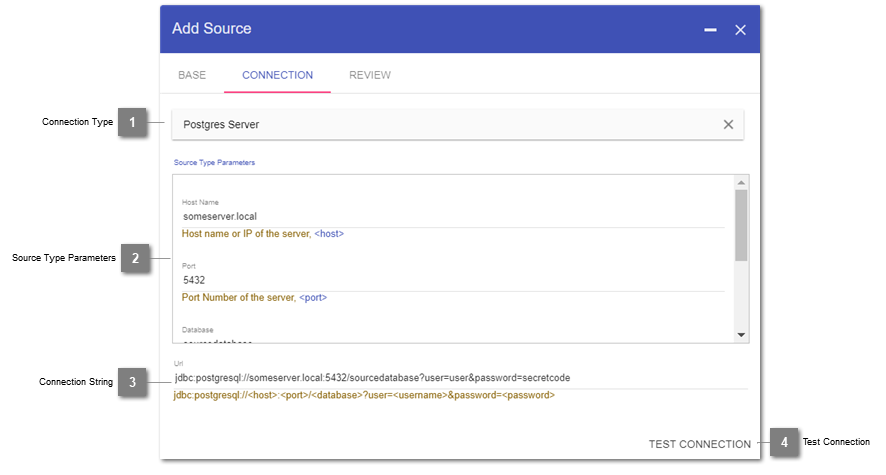
- Connection Type
Declaration of the source type to connect to.
- Source Type Parameters
Depending on the chosen Connection Type, the Datavault Builder will require you to fill in the connection properties.
- Connection String
Based on the declared connection properties, the jdbc-connection string is put together. The string can directly be manipulated to use properties, which are not yet possible by using the source type parameters block.
- Test Connection
By pressing this button, the Datavault Builder tries to connect to the source by using the specified connection string. The test result will return next to the button within a couple of seconds.
Adding a staging table
Adding a staging table will automatically define a staging load.
- Definition
A staging load is a 1-to-1 copy of the data from the source.
- Usage
These loads can be done as full or as delta loads. The underlying logic to pull a delta from the source can be specified within the creation dialogue of each staging table.
The result of the dialogue is a table in the staging area, consisting of fields with the same or a most similar datatype as the original type in the source. Length-restrictions for certain datatypes are removed, so the data can also be retrieved if a fieldtype is edited in the source. In connection with the built in loading logic, the added staging table can immediately be loaded.
- Steps
Navigate to the staging module and click onto
Add Table.Select an existing system on the base tab.
Select the columns to load on the columns tab.
Fill out the details tab.
Confirm the creation on the review tab.
Base
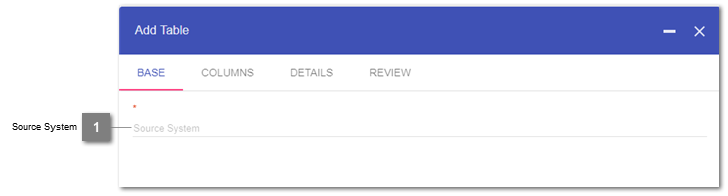
- Source System
Select a previously defined Source System from the list.
Columns
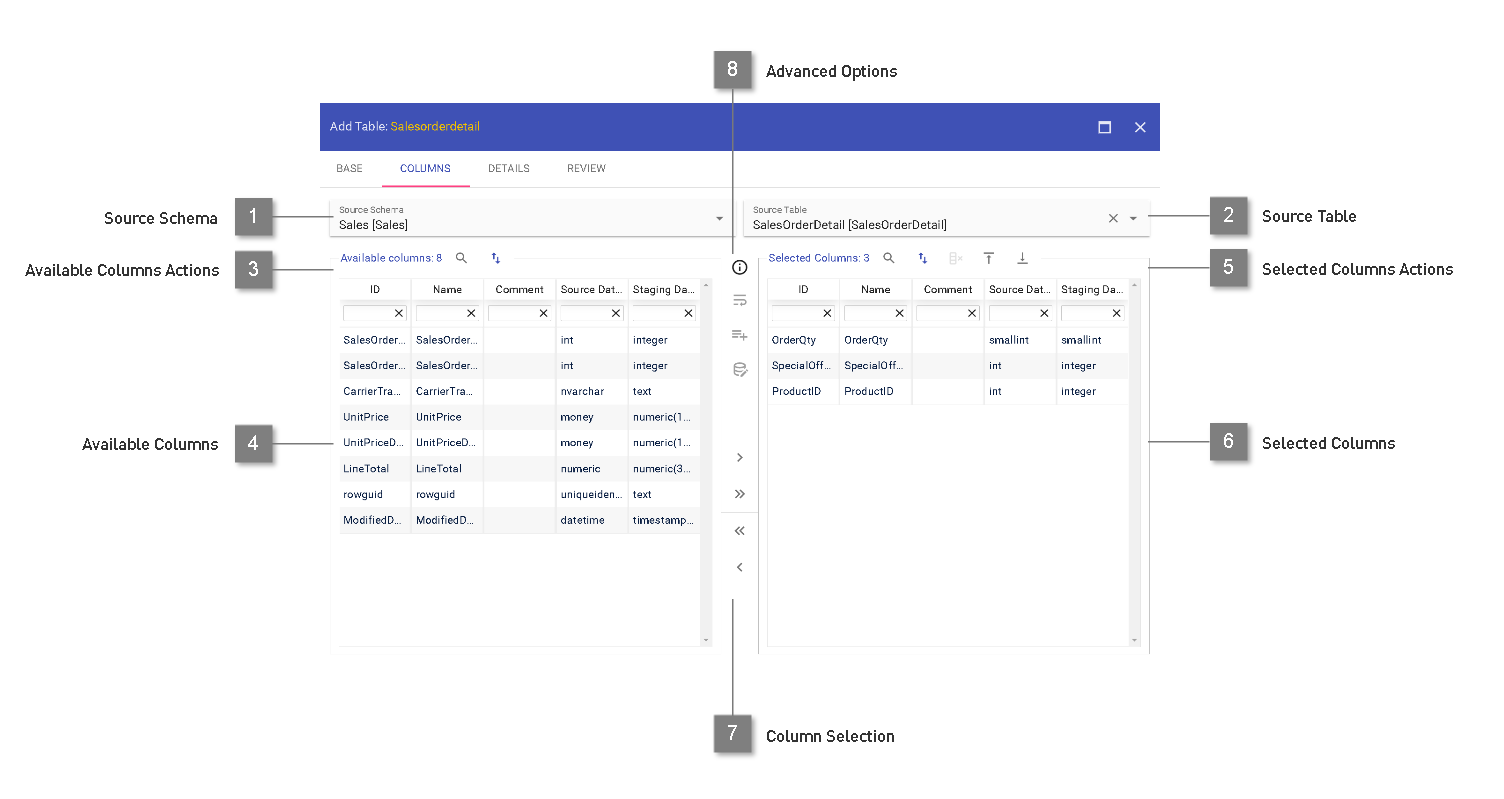
- Source Schema
By scanning the source, the Datavault Builder supplies a list of available schemas. When using Flat Files as a source, the placeholder “Default Schema” shall be used.
- Source Table
A specific table or view within the chosen schema can be chosen. When using Flat Files, this relates to a specific file.
- Available Columns Actions

Ordering of the columns based on source order
Order by column by clicking onto column name; Filtering of columns by any of the columns
Magnifying Glass: Open up Data Preview (if supported).
- Available Columns
List of the available columns in the source object, with column ID and column type
- Selected Columns Actions

Magnifying Glass: Open up Data Preview (if supported).
Ordering of the columns based on source order
Filter for missing columns in the source
Move selected column to top or bottom
Order by column by clicking onto column name; Filtering of columns by any of the columns
- Selected Columns
List of the chosen columns which should be added to the staging table.
- Column Selection
Columns can be added to the selected columns using the buttons in the middle, by double-clicking or drag&dropping. Multiple columns can be selected using “ctrl”+”left click”.
- Advanced Options

Line Wrapping mode to display fields full content on multiple lines.
Add prototype column, which is expected to be filled later on.
Define custom source query for data extraction.
Columns: Source Query
For more advanced use cases, a custom source query can be defined which will override the automatically generated select statement for loads.
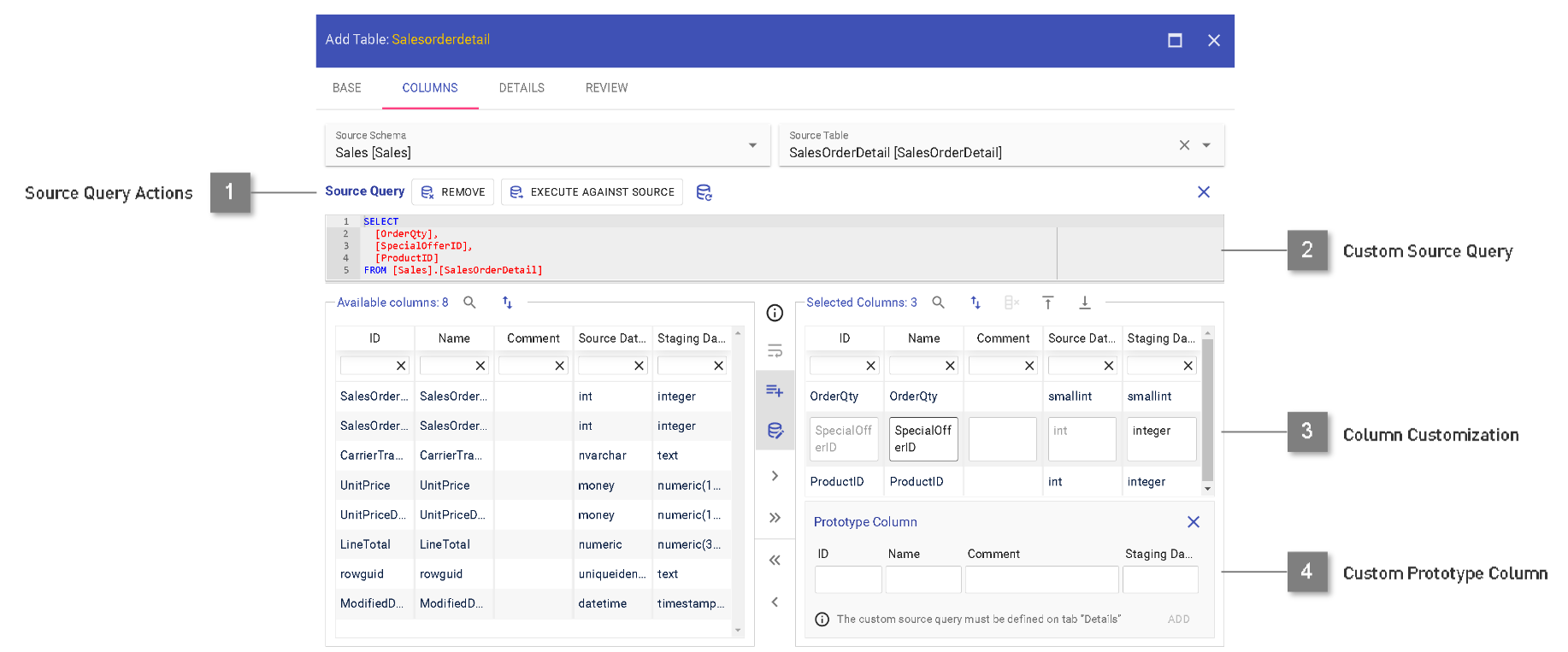
- Source Query Actions
Remove source query.
Execute source query against source (to try and fetch returned columns based on query).
Reset source query based on defined columns.
Close source query editor
- Custom Source Query
Definition of a customized source query. Please check hints below on available variables and syntax.
- Column Customization
Adjust column name, comment and (on creation only) staging data type.
- Custom Prototype Column
Add a column to the staging table which does not yet exist in the source.
Warning
Executing a custom source query can put additional load onto your source system. Make sure to only define queries, which your source system can handle.
Custom source query should only be used if the default process to load data 1:1 from the source is not possible.
When using a custom source query, the parameters for full load subsetting and delta loading have to be manually included into the custom source query and are not automatically applied otherwise.
Steps to use a custom source query
Select a source schema & source table to begin with.
Choose the columns you would like to stage from available columns into selected columns.
Click onto the “Add custom Source Query” button, opening up the source query editor.
The query will be prepopulated and can be modified according to your needs.
You can click onto “EXECUTE AGAINST SOURCE” to test your query. Be aware: This will execute the defined query against your source! For development purpose it is recommended to include a filter condition to not return any data (e.g. WHERE 1=2).
Once the query is executed, the available columns and selected columns list is updated based on the result, so new columns defined in the query can be used for the staging table.
Custom Source Query parameterization
Due to the fact, that the custom source query can include any kind of logic, the subsetting filters can not just be applied onto the query as a whole (e.g. when calling a stored procedure). Therefore, in the source query it has to be defined how the query should look like for different load types. For this purpose you can use freemarker syntax to influence the custom query to be used at runtime. For templating functionality, please refer to https://freemarker.apache.org/docs/ref.html
Available data model:
- context
- is_delta_load # indicates if the current load is initiated to be a delta load
- is_full_load # indicates if the current load is initiated to be a full load
- is_job_load # indicates if the current load is part of a jub execution
- subset
- general_part # general subset part as defined in staging table details tab
- delta_part_template # delta load part as defined in staging table details tab
- delta_part_filled # if delta load part is parameterized, this is the filled up condition
- delta_arguments # if parameters are available for the job execution (running in delta), this contains the list of defined parameters
- parameter # identifier of the argument
- value # as passed in or defined in the schedule
- filled_value # filled in value for the parameter
- system # actual available parameters depend on source type
- source_type_parameters
- database
- host
- port
- Limitations:
data preview is not supported when a custom source query is defined
Samples: Please check our Knowledge Base for samples on the usage of a custom source query as well as for further development hints: https://kb.datavault-builder.com/display/DBKB/Staging+-+Custom+Source+Query
Details
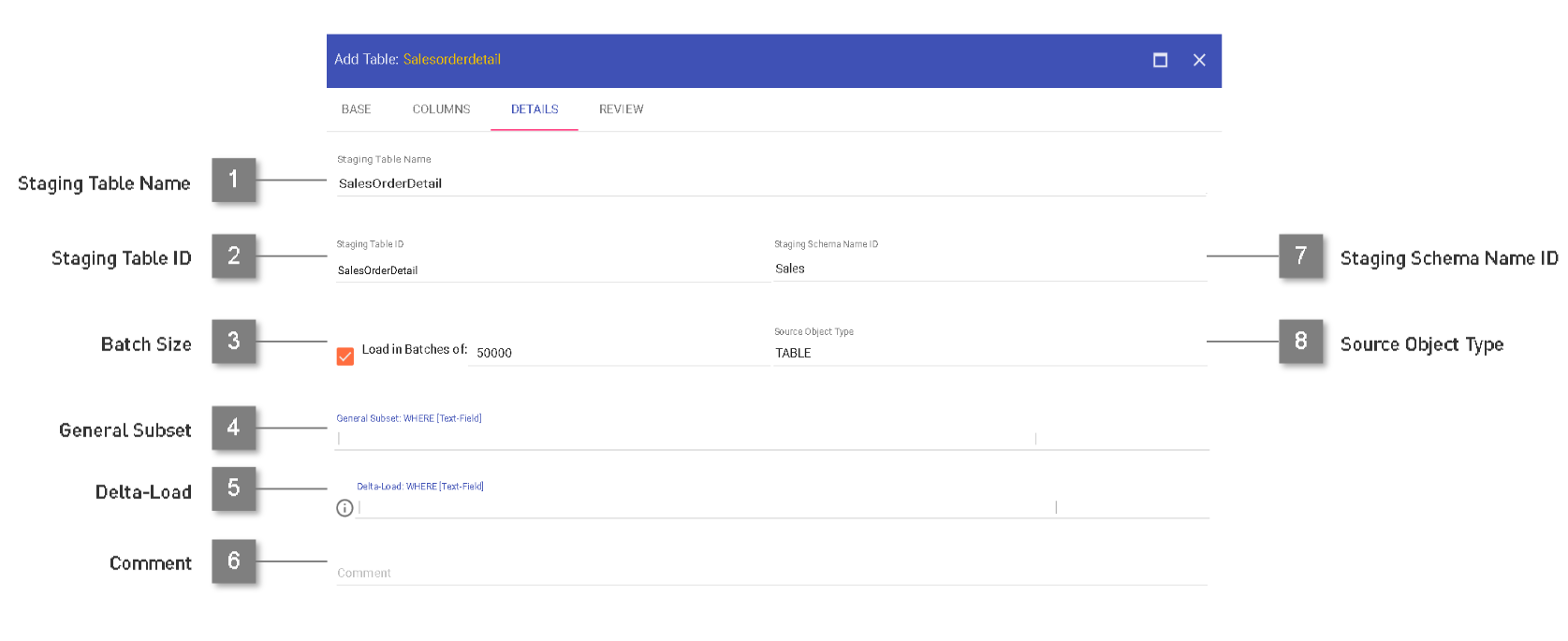
- Staging Table Name
Declaration of the displayed name for the staging table. Editable.
- Staging Table ID
Declaration of the ID used in the technical implementation related with the staging table (between _[rR]_ and _[uU]_) .
- Batch Size
Activation of batch-based loading from the source as well as specification of the batch-size to load in. Editable.
- General Subset
Activation of a fixed subset loading. This subset will however be treated as if the returned data is containing a full load. Editable.
- Delta Load Clause
Specification of a SQL-based where clause statement to perform delta-loads. The where clause can be parameterized using {{parameters}}, to which values can be assigned on execution in the jobs module. This way, it is as well possible to declare different delta loads for the same staging table. Editable.
- Comment
Comment for the staging table, which will as well appear in the documentation. Editable.
- Staging Schema Name ID
Declaration of the ID used in the technical implementation related with the staging table (if set, after the _[uU]_) .
- Source Object Type
Declaration of the type of object which the load is based on (e.g. VIEW, TABLE). For views, on load no count is made for the total rows to process.
Source Specific Configuration
For certain sources, specifc configuration questions may arise.
Generally, you can use the configuration wizard to connect to a source. Based on the wizard, the connection string is automatically derived. If you are missing options in the wizard, then the connection string can as well be directly edited, offering you more advanced configuration options.
CSV
Detailed documentation and advanced parameters to load from a CSV files is available at http://csvjdbc.sourceforge.net/doc.html
Intra / Cross Database Staging
During data extraction from different data sources we currently use JDBC drivers to connect with database sources. Another possibility is the Intra / Cross Staging, where the ELT (not ETL) process no longer takes place via JDBC, but directly on the database. For the intra/cross database loader to work properly, the following privileges need to be granted on the source table or view:
- Staging load performed by a scheduled job of datavault builder:
GRANT SELECT ON <schema_id>.<table_or_view_nq_id> TO dvb_admin;- Staging load performed by a manual load:
GRANT SELECT ON <schema_id>.<table_or_view_nq_id> TO dvb_user;- Databases supporting intra loading:
Postgres
Oracle
Exasol
- Databases supporting inter loading:
Snowflake
MS SQL
Sources with only shipped configuration (missing driver)
For some source connectors, Datavault Builder is shipped with the configuration for the connector, but not the necessary driver. Usually, this is due to license terms restricting redistribution. In these cases you will see an error message when trying to connect to a source system saying:
Could not establish connection: Error loading JDBC driver: <driver class>
- This currently includes source connectors for:
Google BigQuery
InterBase
Neo4j
SAP HANA
In that case, follow these steps to manually add the necessary driver
Download the jdbc driver from the manufacturer
Hint
remove the version number from the driver as the configuration is pointing at no specific version.
for some sources (e.g. Google Big Query), additional configuration may be required: https://kb.datavault-builder.com/display/DBKB/Source+Connectors
Samples:
ngdbc-2.8.11.jar > ngdbc.jar Neo4jJDBC42_1.10.0.jar > Neo4jJDBC.jar GoogleBigQueryJDBC42.jar > GoogleBigQueryJDBC.jarStore the file on the Datavault Builder host in your preferred <directory>.
Map your previously created <directory> into the connection pool (in the docker-compose.yml) onto internal path /opt/datavaultbuilder/lib/manual_jdbc_drivers/:
connection_pool: volumes: - <directory>:/opt/datavaultbuilder/lib/manual_jdbc_drivers/When the jar is stored in directory “manual_jdbc_drivers” next to the docker-compose.yml, then the mapping would be:
connection_pool: volumes: - ./manual_jdbc_drivers/:/opt/datavaultbuilder/lib/manual_jdbc_drivers/
Limitations
Staging data type must be a valid data type on the target. The source data must be implicitly convertable into the custom data type.
Reserved Keywords/Unsupported Characters: A staging column must not match the following patterns:
_dvb_%
%_bk
%_h
%.%
In these cases, a custom source query must be defined to perform a technical renaming of the column(s).
The size of a custom query is limited by the max length of the comment / extended property of the used target database (E.g. Exasol 2000 characters for whole comment, MS SQL 7500 bytes for extended property).