Integrating and Unioning Data
In Data Vault Modeling, we use hubs to integrate data. This is one of the main reasons we choose Data Vault modeling.
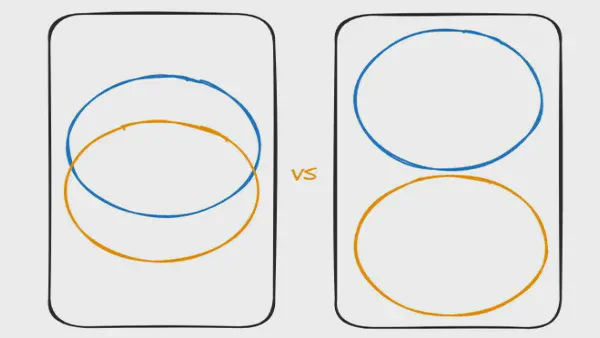
Unioning Versus Integrating Hubs – Why It Matters In Data Vault Modeling, we use hubs to integrate data. Everybody knows that. This is one of the main reasons we choose Data Vault modeling: to integrate data from various data sources. But what does “integration” mean? So far, I haven’t seen a discussion on how we actually integrate data.
In this article, I will simplify my examples, knowing that reality might be more complex than presented here. However, for establishing the main concept, it should help to keep it simple.
In discussions with Carsten Schweiger, we have identified two different patterns: Integration and Unioning.
Integration vs. Unioning
This distinction is important as it changes how we can optimally process the data. Let’s characterize the two options:
Integration
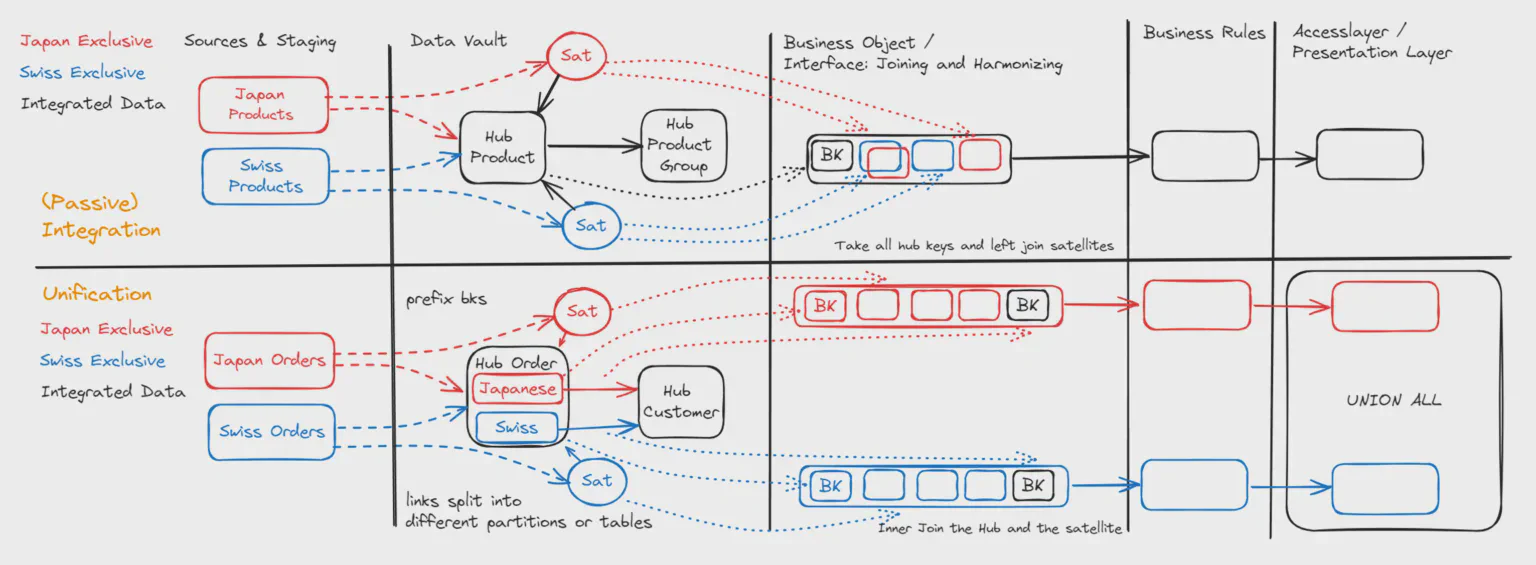
Also called passive integration: we have two different source systems with the same business key. An example I often see is the Product with the Product Number, which is shared more or less successfully between different systems.
If we want to compare the list price in Switzerland and Japan, we can load the Swiss ERP data and the Japanese ERP data into the Product Hub. The Product Number is loaded without any prefix into the hub, and the attributes are loaded into a Japanese and a Swiss Satellite.
If we now create an output interface on top of the Data Vault (in the Datavault Builder, we call this a “Business Object”), we will select all the keys from the hub. We can then put the Swiss list price into one column and the Japanese list price into another column.
If the Swiss list price is the master but there are some Japan-exclusive products, we could create a third column with some prioritization rules like: if the Swiss price is filled, take that one; if the Swiss list price is empty, select the Japanese one. This is the use case we, at least I, usually have in mind when we start a Data Vault project.

So why do we need to differentiate Unioning? It differs in that the data sets coming from two different data sources are non-overlapping / exclusive. A common example is the Order Hub. The orders from Switzerland and Japan are unioned in this hub, but Order Number 101 can exist in both Switzerland and Japan, though it is not the same order by business definition.
This means that
-
we need to prefix our order numbers to keep the data sets separate, and
-
we don’t need to invest compute power to try to combine orders from the two source systems with some clever magic
-
we can keep the data separate until the presentation layer reducing the amount of data needs to be joined
-
we can fully parallelize the processing of these two data streams when loading into the Data Vault
-
we can fully parallelize when selecting data from the Data Vault
The good thing is that usually the big data sets are Unioning and not Integrating data sets.
If we accept a general category of Unioning Hubs as its own pattern:
-
We need to prefix the business keys for the hub loads as there might be overlapping number (value) ranges that do not mean the same thing.
-
We can create link tables partitioned by system (or separate link tables). This allows loading them in parallel
-
This allows reading them more efficiently as the number of rows joined is reduced for every source system, and this reduction is exponential in relation to the number of source systems.
-
Output can be prepared separately. Column name harmonization can be done virtually on a per-system basis.
-
Business Rules can be processed on a per-system basis.
-
Creating the unioned output: In the end, we can use a generated UNION ALL statement to combine the data sets from the different sources.
-
This allows the database to parallelize the selection of the different source data sets and also to push down filters on specific data sets to the Data Vault.
This allows faster preparation of the full data set but allows also filtering on separate systems and push down as well filters on specific satellite columns.
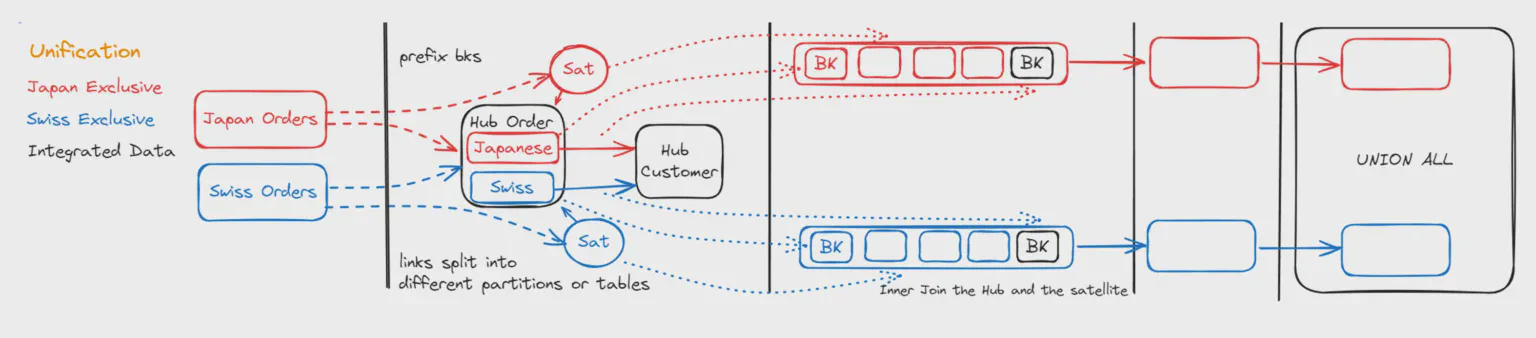
By differentiating between Integration and Unioning, we can optimize the patterns for entities with large amounts of data. Additionally, expressing this information in our data model clarifies the purpose of the data integration pipeline and helps determine which objects can be joined for meaningful output.
How to Automate Integration and Unioning
You can see in the following video how these two use cases are configured fully automatically in the Datavault Builder:
See Datavault Builder in action
20-minute demo. Honest answers on whether it fits your team.
Book a Free Demo