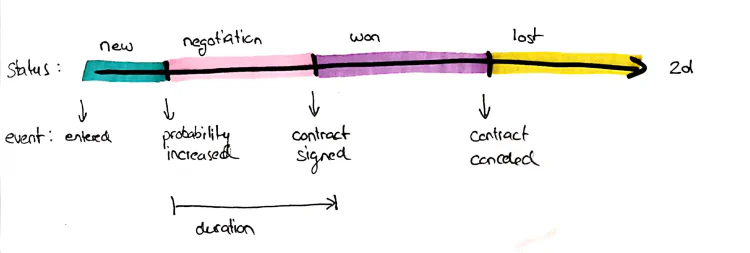
DWH Temporality Part 3: Outputting Timelines
Although in many cases it is not necessary to output the timelines in the reports, there are some cases where the output of timelines is important.
Although in many cases it is not necessary to output the timelines in the reports, there are some cases where the output of timelines is important. Examples are:
-
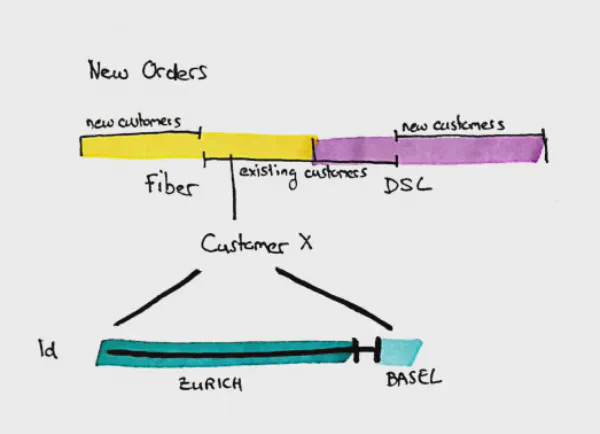
Displaying a customer history (1d)
-
Highlighting subsequently modified data to identify fraud and legitimate corrections (2d)
-
Flexible comparison of different time periods to understand relative changes (3d)
If you haven’t heard yet about 1d (Business Validity), 2d (Inscription Time) and 3d (Load Time) you might consider reading the first part of this series.
Output the 1d timeline: Example customer history
You may want to drill down to a single case in reports that show aggregated values. In order to understand the individual case, we might want to understand the history of a customer: when did he live in which region and when did he change which subscriptions. An example could be that we see that existing customers cancel their DSL internet connection but later are ordering optical fiber internet. To understand what happened it might be useful to pick out some samples, analyze them to create new business rules to understand such use cases as well on the aggregated level later. This is a 1d history: the business validity.
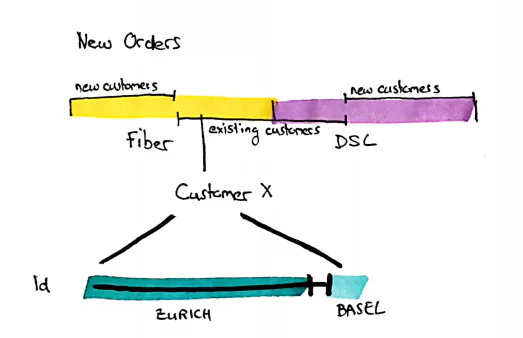
As we have already learned in part 2 of this article series, you can store this in a Temporal Instance Hub by adding the Valid From Date to the Business Key. Since the grain of the hub and the data to be output now match, I do not need to make any modifications to the output. The only thing I have to take into account is that a shift of a time slice on the 1d time axis in the source (change of valid from time) is recognized by the DWH as one deleted and one new time slice as the valid from time is part of our key. This means that we have to mark or filter the no longer valid version of a time slice.
We achieve this by remembering in a tracking satellite whether a key is still present in the source or not. Important: this only works with full loads. This is independent of the Datavault Builder tool and even independent of Data Vault. If I don’t get an explicit delete message from the source, I as the receiver can only detect implicitly deleted lines by a full load. However, this full load must only contain all parts of the business key and not all attributes. It is, therefore, possible to load the attributes delta and only load the key and valid from time fully in order to recognize such “deletions”. If I now output these rows in the report, I will now join the tracking satellite and either filter all rows that are no longer in the source out in the DWH or at least mark them as deleted on the interface to the reports and implement a pre-selected filter in the report.
![]()
Since the creation of the corresponding tracking satellites and also the readout as a virtual field in the Datavault Builder is automated, I will not go into this in detail. But if someone wants to implement such a Full Load Tracking Satellite by himself, he only has to compare the BKs (technically the hash of it will work also) with the hub and intersect the two data sets: business keys present in the hub but not in the staging table need to be marked as FALSE and all others as TRUE. Alternative methods to detect changes in time slots
If the source system at least reliably delivers real deletions (i.e. not just shifts that we perceive as deletions), you can also build a CDC with the help of a Persistent Staging Area (PSA). I refer to a PSA, which creates a SCD type 2 history on the 3d timeline based on technical keys and not a complete snapshot PSA.
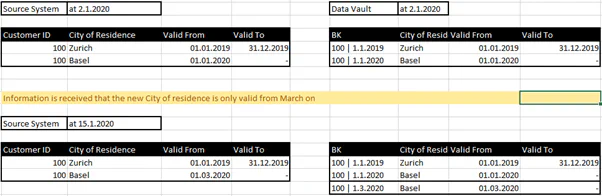
If time slices at the source system are captured with the same technical key, we can see that this is a change and not a Delete & Insert:
Based on this information, using a “Partition By” BK on the satellite, in this case, the source technical key that is filled into this field, we can select always only the last entry to get only the relevant information. This can then be stored in a new hub and satellite customer, or simply output virtualized. In any case you should reduce the 3d timeline by an as-now cut before you make the data available to someone else. This means that the 1d timeline is output, but only with the current status according to the 3d timeline.
It is important to me to point out the inherent beauty of this approach, that unlike other variants you don’t even have to calculate any surrogate keys. The individual entries are clearly represented by the BK + Valid From or representatively by the corresponding hash and also all references are already prepared on this grain. No lookups. No ugly in between joins. Just output the data.
2d Timeline: Detecting Fraud
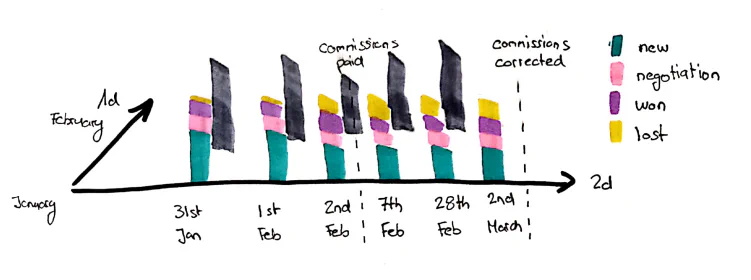
A few years ago, I was asked to follow up on some irregularities in the sales commissioning of a customer. There were different rules for when a salesperson was entitled to a sales commission. On the first day of each month, they looked at how many new contracts a salesperson had signed. The delivery and invoicing of the product were sometimes quite fast, but because certain products were not in stock, it was not possible to deliver them until 2-3 weeks later - which delayed invoicing. Few sellers have used this to record contracts on the last day of a month and then cancel them retroactively the day after the commission was calculated. On a single purchase order, it now looked as if the seller had entered the contract and deleted it on the same day. This was a perfectly normal scenario since after the contracts had been entered, a confirmation step followed in which everything was read to the customer again and to which he had to agree. For commissions, on the other hand, the contracts were counted. However, if the same report was created 2 days later, it looked completely different and clearly identified the corresponding salespersons. But if fraud had been the only reason for this pattern, you could have simply canceled the corresponding salesmen and would have been good. The point is, however, that such business processes can be partially legitimate (such as a 2-week cancellation right in certain markets). What are potential solutions to this problem: assuming the source system records every change with the Inscription Time, you can use it to trace the history. In case of a fraud pattern, which also occurs between two DWH loads, this would be the only possibility. In this case, however, the sellers had to wait until the data had been transferred to the data mart. This would have allowed the fraud pattern to be clearly documented using the 3d time axis but would have been less accurate and more difficult to understand to the salespeople not committing fraud which needed to verify their sales commission numbers.
Case 1: 2d time stored in the source, but without history
So how do I deal with this data? If the source system records the Inscription Time, but does not keep a history of every change, I have to create the knowledge of the 2d history using the 3d history in the DWH. As already explained in the second part of this article a 3d history is only an approximation in such a case and the better the more often the loads into the DWH take place. For intraday loads or even for streaming loads it can become almost a perfect approximation in the end. Example: A contract changes on January 29, 2020 (Inscription Date) from state: Offer to Closed. Business validity is also given as 29 January 2020. The same contract changes on February 2 (Inscription Date) from Closed to Lost. So I can create a hub with a satellite, which in the hub BK either only compiles the business key of the contract, or in case of a 1d history in the source the business key + Valid From time. This is completely independent. We recommend to simply store the 2d times as satellite attributes. This means that at the time you are storing the data you don’t need to understand all business rules on how to output them. This is, by the way, a big paradigm change in Data Vault compared to Inmon 3NF warehousing.
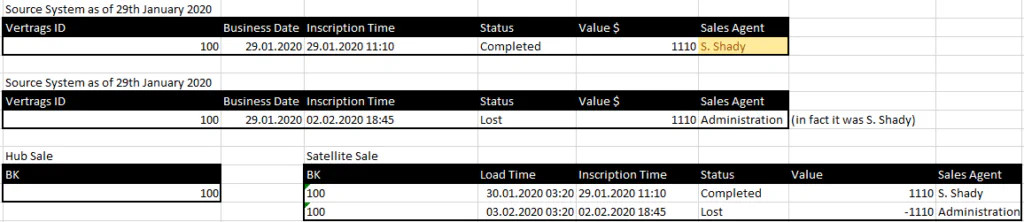
The difference is, that I can not only access the last data on the 3d history (as-now), but I have to evaluate the timeline on the 3d timeline to reconstruct the 2d timeline. One idea could be to output the satellite data that you have with 3d history to the reports. Technically correct, but probably not very helpful. Because then I have to add the appropriate logic to the reports to reconstruct what actually happened. Because what I’m actually interested in: on the one hand the conclusion of contracts and the dissolution of these contracts on an unchangeable time axis. Since the assumption is that in this case changes can be entered retroactively on the 1d time axis, we use the 2d time axis for our evaluation. And we can derive events from the change of attributes, here primarily on the contract status, on this time axis:
In the following output, we have already implemented the first rule that the value becomes negative for the event “Lost”. But we can already see here that S. Shady was clever. He changed the sales agent here so that the cancel event is not credited to him.

So we introduce a new rule, which takes the Sales Agent from the last “Completed” event:

And then S. Shady’s sales in February will be reduced by the lost contract. But that in turn only works for linear sales commissions. Otherwise, you have to derive the time period for which the correction applies:
![]()
And at the latest here you will see: the requirement to simply play out the data in SCD type 2 form, as stored in the satellite on the 3d axis, does not help anyone. Only by interpreting the events on the different time axes, useful knowledge is created. With the data prepared as above, I just need to aggregate in the report based on the Inscription Time. Also, I can use the Correction Time to understand what changed since my last analysis.
I agree with Michael Müller when he states: As these requirements become more complex. As business defines more business rules to correct the attributes on the timeline, one might be better off by putting all the logic into one business rule module and have a very simple history. But without business requirements, we can only pass on the basic data and the derivation of the knowledge must be done in the report. And the reporting tools I know are not well suited to make inter-row analysis. It is important to understand: by storing the 2d timestamps in the satellite with a 3d history we can later derive all possible views and interpretations through the correct query logic. So the recommended procedure from part 2 of the blog still applies: *** 1st simplification / strategy : store the 2d times as normal satellite attribute*** With the addition: if the 2d is relevant for the analysis of the data, this can be done at any time during output by interpreting the 3d history.
Case 2: 2d time stored with history in the source, no 1d history
If we already receive a 2d history from the source, our source data is thus a pre-historicized table. If the source now contains 2d history but no 1d history, then it can be assumed that the 2d history can be equated with the 1d history as it is probably the best approximation. This means that it is assumed that certain information changes over time, but that the information valid at that time is still relevant. But in contrast to a complete native 1d history, no retroactive or future changes can be recorded. Where will you find such a case: possibly in source systems that cannot record a 1d history, but you have created triggers in the database to write the overwritten or current version of the record to a history table at Inscription Time.
Some databases have even implemented this concept by default. Like “system-versioned temporal tables” in MSSQL or “temporal table” in Teradata. Not to be confused with Oracle’s Flashback archive or Snowflake’s Time Travel. In the first case with MSSQL and Teradata, the Inscription Time is available as a single column. In the second case of Oracle and Snowflake, queries can be executed as-then very easily but for a single time slice at a time.
If a 2d history is used as an approximation to the 1d history, it can be treated as a 1d history.
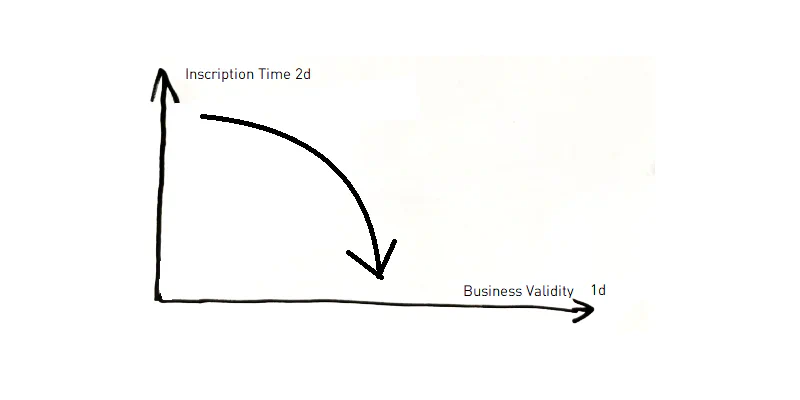
It is therefore valid from the second article: *** 2nd “simplification”/ strategy: create a temporal instance hub ****** by concatenating the business key with the business valid from time*** How the 1d history can be output can be seen in the first chapter of this article.
Case 3: 2d time stored with history in the source, combined with 1d history
If we already have a bi-temporal data source with 1d and 2d history, then we are probably with an insurance company. To all other readers: you can skip this chapter, fortunately. For our friends of the sophisticated insurance business: there are two ways to load such source data into the Data Vault.
-
Combining the business key with the 1d Valid From timestamp and additionally adding the 2d timestamp
-
Take over the technical key of the source and store it as Persistent Staging Load (PSA Load)
Why can’t we just store the 2d timestamp as an attribute in the satellite in this case? Because the grain is not correct: we do not get only one record for BK + Valid From Time at a given time, but several if there was a correction for this 1d time slice. Solution 1 would be the preferred solution from Data Vault’s point of view, because it is based on significant keys. My personal experience is:** take option 2**. Somehow source systems always manage to produce more than one record for the same entry on the 1d and 2d timeline. This goes back to the chapter: never trust any source system ???? From this hub with 2 histories, a new hub can be derived with an exclusive 1d history in the hub key and the 2d history in the satellite as an attribute using a business rule which selects only the latest record on the 2d timeline = makes an as-now cut on the 2d axis in a business vault load. Thus we have reduced a new pattern to a known pattern. For everything else see above.
Variant discussion
With this pattern you can now place a pointer between the hub with 1d history only and the one with 1d & 2d history, which points to the current entry in the second one. So it is not necessary to copy the attributes from the 1d & 2d Hub to the 1d Hub.
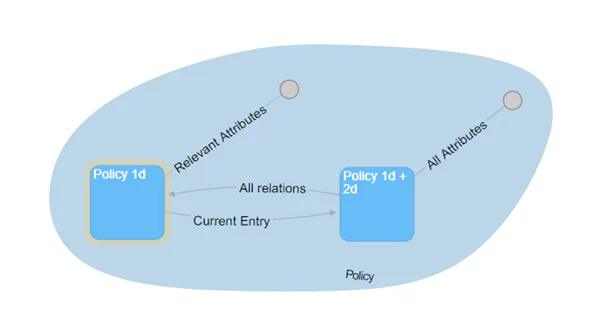
Above is an example where in the PSA Load the “Policy 1d + 2d” Hub is loaded directly from the source and all attributes are historized based on the technical key. Also the hub “Policy 1d” can already be filled with the keys (distinct load). An “all relations” link could also be filled directly from the source. This makes sense, for example, if the “1d & 2d” are to be provided with enrichments on an interface of the DWH maybe for fraud analysis or process mining. I would recommend in such a case to make an as-now cut on the 3d timeline because even 2 timelines in a report are very difficult to understand.
A Business Vault Load then filters to the last valid entry per 2d timeline and then either fill only the link Current entry, which has configured the “Policy 1d” page as a driving side, or even copies certain relevant attributes and attaches them directly to the “Policy 1d” hub. With the second variant, the 3d historization in the satellite creates a 2d timeline stored as an attribute (from the time the satellite is loaded).
With this modeling, I can now choose all possible variants for the output to data receivers.
Output the 3d timeline: Reproducing and comparing knowledge levels
A frequently cited case for output the 3d time axis is the reproducibility of reports. This is a very important requirement, if e.g. reports, which were created for legal reasons, have to be reproducible at any time. Be this for Sarbanes-Oxley, Basel I, II or III or whatever they may be called reporting. This requirement is absolutely real, but can be solved sometimes in some databases with house remedies. Oracle offers the Flashback Archive for such queries at a certain time. Snowflake offers a similar feature with Time Travel, with the difference that you do not have to sell your organs to finance it. With Snowflake, a simple SELECT x,y,z FROM a,b,c AT [TIMESTAMP] is sufficient. This currently works for 90 days in the Enterprise Edition, otherwise only 1 day. There is also the possibility to save certain time periods on the 3D axis as a new database with CLONE AT. Only the pointers are copied to the data and you do not have to pay again for the complete database.
Reproduce knowledge levels
Another simple variant is to use report tools that read the data into their own structure such as QlikView / Qlik Sense to save the reports created in this way. Since such reports can also include detailed data in addition to the aggregates that usually have to be submitted, this can sufficiently fulfill the requirements for reproduction on a key date. The difference is that the database variant allows comparisons between two different time periods, but the solution with saved reports does not (unless I re-import them into a database). The solution corresponds to the procedure described over and over again: to make a cut on the 3d axis as an as-now view and then save this view away.
Compare knowledge levels
But do I want to give a report the possibility to call up the state of knowledge of each day and compare 2 or more states of knowledge?
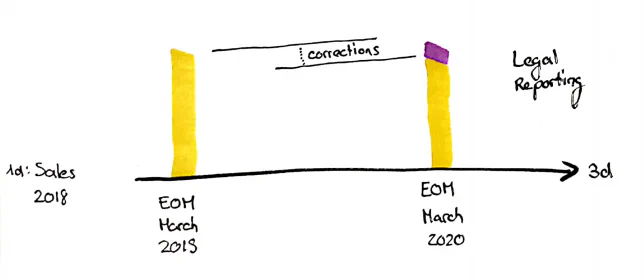
If you understand the requirement of the business user and share his point of view - or if you are hierarchically subordinated to the requestor, then you have to create a SCD type 2 output for the 3d timeline. I describe the technical implementation in the fourth part of this series.
Epilogue
My personal opinion: In the next article, I will finally deal with how to technically create an SCD Type 2 output for the 3d timeline. What was important to me in the whole context up to this point is to show that in most companies this should be the exception rather than the rule if there is any need at all. If you use an SCD Type 2 for the 3d timeline as standard, you probably do it because you can and because nobody has properly collected and/or analyzed the needs of the business users. Of course, Ralph Kimball, who described this as the standard pattern for his data marts, may also be involved. Or also the many other authors who describe the creation of PIT tables in a technically absolutely correct way assuming that you know when to use them. All these texts are also completely correct. But if I send the data in such a format into the reports, I will, if no technical requirement justifies this, make them unnecessarily complicated and make Self Service BI something between difficult and impossible.
See Datavault Builder in action
20-minute demo. Honest answers on whether it fits your team.
Book a Free Demo