DWH Temporality Part 2: Reducing Complexity
How to reduce temporal complexity in the Data Vault. Datavault Builder users frequently ask how to map changes over time correctly.
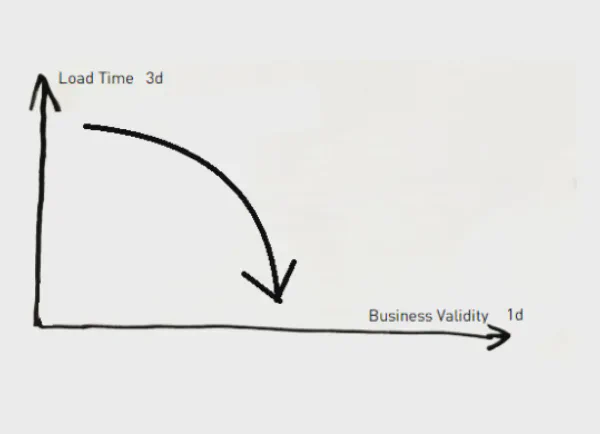
About “Temporality” in the Data Vault
Getting rid of the temporal complexity
As the manufacturer of the Datavault Builder automation software, we are frequently asked how to map the changes over time in our tool and/or in the Data Vault in general. Often in the form of: how can I report SCD Type 2 stuff. However, it is sometimes not clear which time axis we are talking about. Therefore, here is an attempt to clarify this. This is the second article in a series of three.
-
The first article defined the challenge we are facing with temporality in the DWH
-
This article defines possibilities to simplify the temporal complexity if possible
-
The third article discusses business requirements to output timelines
-
The fourth article will explain how to technically output the 3d timeline as SCD type 2
There are different approaches to temporality in the data vault. I would, therefore, recommend reading the texts by Dirk Lerner, Christian Kaul, and Lars Rönnbäck. I present here a variant of how to represent or simplify the various time lines in such a way that they can be brought under control. I will also publish a follow-up article on what to do if such a simplification is not possible because the business requirements demand more options. As defined in the first article I’m discussing only 3 time lines and I use the following shortcuts:
-
1d for Valid Time
-
2d for Inscription Time
-
3d for Load Time
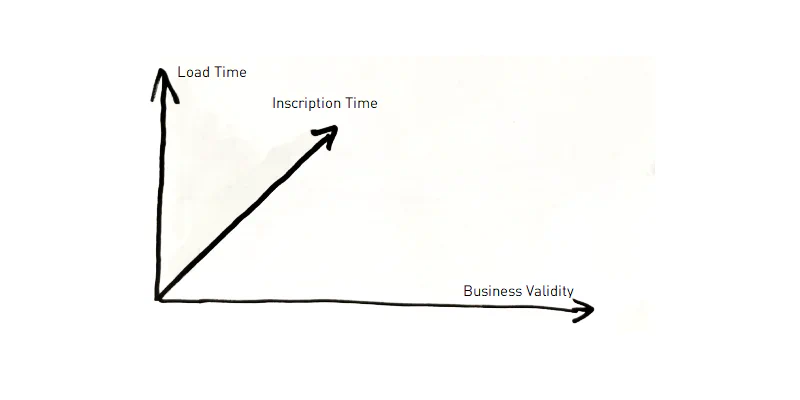
The first dimension (1d) is the business validity. This timeline is special in the sense that a new time slice on the timeline does not mean the old entry is invalid: if I live in Basel instead of Zurich, the information that I once lived in Zurich is not incorrect *1. If I report a future place of residence, not even the information about the currently valid place of residence is changed. So we have various pieces of information that were current at different times, but are still all correct and therefore valid.
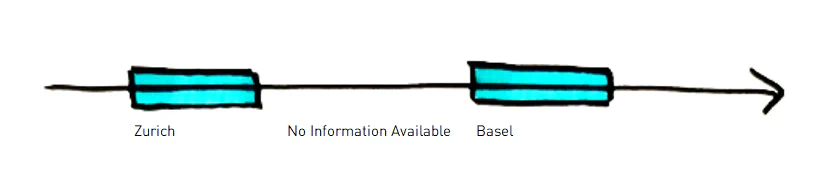
1d axis: All information is valid but only one entry is current. The second dimension (2d) is the inscription time in the source system. This is relevant because on the 1d axis you can also enter new entries for the future and corrections for the current time slice and/or the past. In certain industries and departments, this can be used to commit fraud. As an example, sales commissions can be obtained by recording and subsequently deleting contracts that do not really exist. Thus, this timeline can be crucial for auditing and fraud prevention. For normal reporting, it can often be disregarded - especially if the third time axis is not very far from this second time axis (e.g. through daily or even intraday loads). And this is also the reason for the first simplification: I suggest to store the 2d timeline in a satellite simply as an attribute in a first step so that no information is lost and later special analysis is possible if necessary. But in this text, I will not deal with this case explicitly. *** 1st simplification / strategy : store the 2d times as normal satellite attribute*** It means that from the 3-dimensional space we only consider a 2-dimensional plane:
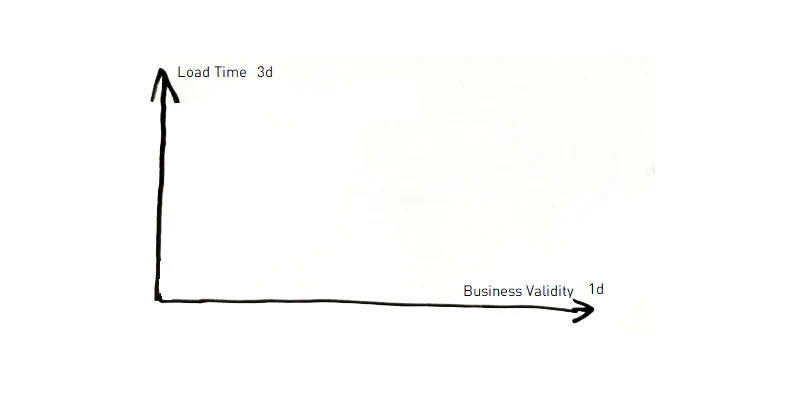
The third dimension (3d) is the time when the information has been loaded in the data warehouse. There are still different nuances, whether you enter the time, when the data was entered in staging or in the core and whether you set a time for the entire batch load or for each individual section. Again, I do not want to go into the discussion too deeply. I would be happy to discuss this again in a separate text. We set the time when a leg is loaded into the core so that we could restore the information at certain query times. If the staging time is relevant, I would keep it as an attribute in the satellite. But this does not mean that I consider different views to be wrong here, just different. The 3d axis is special in that it is under the control of the DWH team. And many who have been working in this area for a long time know that we do not trust any source system :)

3d axis: One information replaces the other implicitly (yes, Petr is the correct spelling of my name)
What are we talking about / corrections vs. real history
If we now assume that the load into the DWH is very close to the acquisition in the source, we simply store the 2d time as an attribute in the satellite and ignore it in a first step. So when we talk about SCD type** 2: is it 1d or 3d?** This is not always clear and depends partly on the industry. In the insurance business, for example, it is mandatory to keep a 1d history for many objects in the source and therefore for most insurance users this is the primary time dimension. In other industries, it is rather less known (maybe except for a few objects like the address) that the data already has a 1d history from the source and therefore the 3d becomes the primary time axis. It is important to understand that in a perfect world the 3d axis would actually have exactly one purpose: to show what the DWH knew at a certain time. An example could be that on February 2nd the commission payments for January are calculated and the report is reproduced exactly the same weeks or months later, even though the data in the source system has changed in the meantime, because, for example, certain contracts were not concluded as entered. Above all, because you do not want to take later corrections into account or because you need to show the uncorrected figures with explicit corrections reported. The problem is that certain data, which should have a 1d history in the source, do not have one because the source system, to put it simply, does not support this. For example, for certain evaluations for the logistics department, it may be relevant that for my first order in an online shop I was living in Zurich, but lived in Basel for my second order. Thus the 3d axis is taken as the best approximation to the 1d axis if the address is not already instantiated by the source system.
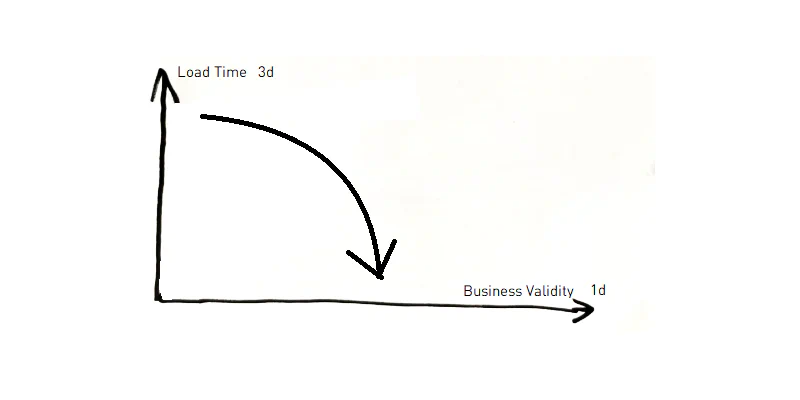
In some companies this is so common that no distinction is made between 1d and 3d. Now there is another complication: if there is no distinction between history and correction in the modeling, even more things get mixed up. For example, if my first name is corrected in the source system, this is usually a correction. Even if we store it in the Data Vault as a new entry in the satellite for traceability reasons, it is not a business history. It happens very rarely that someone gets a new first name. Nevertheless, I have seen at some companies that exactly this change has been transported in the form of a SCD type 2 dimension right into the reports. This not only makes reports unnecessarily complicated, but may even make them incorrect. However, as we sometimes cannot distinguish between corrections and real history like the change of surname when getting married in certain countries, we might have to choose the pattern that covers the majority of expected cases.
True history vs. relevant history
But even if there is a real history: if it is irrelevant for my business model what a person’s name was (unless I sell name mugs): Why do I put this information into a report? These are questions as Michael Müller puts it correctly to be answered by the business users. But as we need to expect that future business users will change their minds about what they need we still store the full history in the 3d time line. This doesn’t mean that we output this information into the reports. Concretely: only the current customer name on the 3d axis may be relevant because I compile mailing lists from my reports to inform certain customer groups about new products or because I have to organize a callback. But it is irrelevant whether the name was corrected or whether the person effectively had a different name at some point. The same applies to 1d history already recorded in the source: for a mail merge, it does not matter where the customer had lived in the past and where he will live in the future. Only the currently valid place of residence in regards to 1d and 3d counts. So my assumption is that, depending on the goal of the evaluation, we need to bring real 1d business history into the reports or where not available but relevant, use the 3d axis as the best approximation for 1d. *But in many cases it makes more sense to provide a point in time view (depending on the business needs that may be on a per attribute level as-now, as-then or as-of point in time) into the reports, because it makes it easier to use the reports and decreases the chance to evaluate something wrong. 2 In fact, it is a cut through our 2-dimensional time plane to a time line.
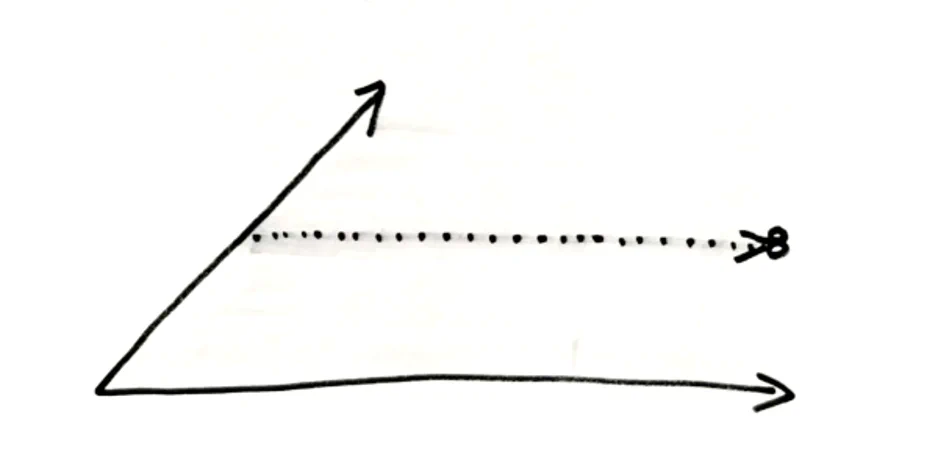
And from time line to point in time

An example requirement could be: I want to know the customer address as-now on the 3d axis and as-now on the 1d axis. I will get the most current name according to our latest knowledge. Or I want to know the department of a sales person as-of 31st January 2020 on the 3d axis but at the time a contract was signed by the customer (as-then) on the 1d axis. The second example says: I don’t want to know about any corrections the data warehouse learned about after the 31st of January and I want to know the department in which a sales person was working at the moment he closed a deal. I don’t want to reassign his revenue if he changes departments later.
How to model 1d history in the DWH *3
There are some basic differences: do I interpret the time before loading it into the Data Vault (see also the good works and courses by Dirk Lerner) or do I first load everything coming from the source into the Raw Vault, even if we get overlapping time slices. We have chosen the second approach because traceability in the vault itself for us is only given when we can capture all data, however wrong it may be. *** 2nd “simplification”/ strategy: create a temporal instance hub ****** by concatenating the business key with the business valid from time*** This means that we receive several valid entries for a business key, such as a contract number, even if they are not current. We thus receive several tuples with descriptive attributes for the same business key. In the Data Vault pattern, a satellite can store exactly one tuple for a business key during a load. This is confusing in that it can have multiple tuples over time. But these tuples represent the 3d history - not the 1d history where there are several valid tuples at the same time. The solution is either to use a so-called Multi-Active Satellite (MA Satellite, also called Multi Valued Satellite - some modelers may call it explicitly a Bi-Temporal Satellite) or to change the grain of the hub. I call this a temporal instance hub. Both approaches have a for and against. The MA Satellite makes the model leaner from the point of view that no special hub for a bi-temporal version of the object needs to be introduced. The drawback is that I can no longer reference a specific instance of the object in the model. *4
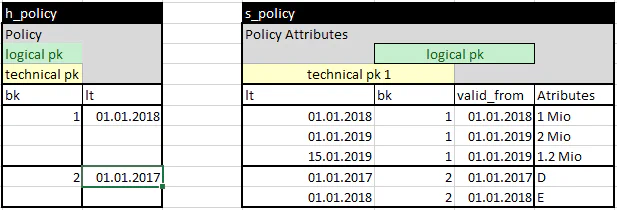
Example: In insurance, I have a policy with a defined coverage. However, this coverage can be adjusted over time. Important: this is normally not a correction, but establishes a new instance of the policy. For example, my coverage for 2018 can be 1 million, which I increase to 2 million in 2019. Now a claim is reported. The customer will report it in February 2019, but it is determined that the damage has already arisen in November 2018. If I have now chosen the solution with the MA satellite, I can only link the damage to a specific policy as a whole and I have to define the selection of the appropriate policy instance in a business rule to be able to state if the coverage is high enough. If I have chosen the solution with the policy instance hub instead, I can link the claim directly to the appropriate instance.
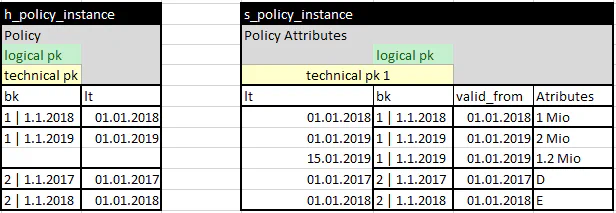
If there is a correction now. because in January 2019 someone finds out that the coverage was entered incorrectly and should be 1.2 million for 2019 instead of 2 million this again causes a problem for the MA satellite: I don’t know without additional rules which entry to replace in the satellite. This makes a possible delta load concept, which already resolves this, a custom load pattern requiring additional metadata. So I may have to move this logic to the business rule part as well, and it is no longer directly visible in the model. Again, the temporal instance hub has a clear advantage here: if only one time slice is changed, it will be updated correctly in the 3d timeline with a standard load pattern, without having to load all other instances of this contract. As the logical pk consists only of the bk column which is defined as the concatenation of the ID plus the business valid from time. For these reasons, we support the temporal instance hub approach in our tool. But as described it is not the only possible solution. And not to be confused with the keyed-instance concept which describes a solution to create a hub to represent the identifying keys of a transaction. So, if I have a temporal instance hub I can also output it including the 1d history with a 3d as-now (also called As-Of-Now) view very easily by just selecting the last entry per business key in my satellite and the structure of my reports becomes trivial. *7
What about relevant dimensional attributes: instantiation
Even though I have described above that certain changes of attributes are not relevant for many evaluations, there are certainly such changes which are central. An example is one of our customers who has the possibility to produce or buy certain products himself before he sells them to his customers. For quality assurance purposes, it is significant whether the product was sold and delivered by the customer or by an external company. Of course, the right way would be for the source system to already record this information. Unfortunately, in this case, the setting in the Product Master System at the time of ordering is the only source of this information. This setting is therefore not historized or instantiated in the source. Therefore, we have to use the 3d history as the best approximation. So, we have the case where a 3d time axis is used as an approximation for the 1d view. If we now stay with the classic Kimball modeling, we would output a sales order line as “fact”. In this case the product characteristics would be output as SCD type 2 “dimension”. Since we do not have a 1d time axis here, the 3d time axis would be used for the SCD type 2 historization and a Valid From and Valid To would be calculated based on this. Again I think using the labels valid from and to for the 3d axis will create confusion so try to omit this. However, other product attributes, such as the product name, should be output without history, since changes to these attributes normally correspond to a correction. This means that the dimension would be transferred to the report once in an SCD type 2 version and once in an SCD type 1 (as-of-now) version. In fact, we now have to include two foreign keys: the business key itself plus the business key combined with the correct time slice - which is often represented by a surrogate key in a Kimball world.
This means additional complexity in the report and additional complexity in creating the fact. Although it now looks as if we could combine different time views, this is usually not the case: the name in this example is always read as-now (as-of-now) and the product property is always read as-then (as-of-then) 5. So what is a simple solution that allows the same analyses in the report, but is simple for modeling the data mart/report view? In Data Vault modeling, there is a very simple way to do this: we can transfer this attribute from the product hub to the sales order line hub. This is done by setting up a Business Vault Load at the time the transaction is loaded into the Raw Vault, which does an as-of-now lookup on the product attribute and then stores it in a Business Vault satellite on the transaction. It’s trivial because we don’t have to do any historical queries on the 3D axis and it’s efficient because we only have to do it for new transactions. The only objection could be that this materialization consumes storage space. But this is not really a problem with databases that support columnar storage, because the few instances of such attributes are compressed anyway. I call this procedure instantiation* of an attribute on another grain**.8 *** 3rd simplification / strategy : instantiate attributes at a certain point in time to the transactions**
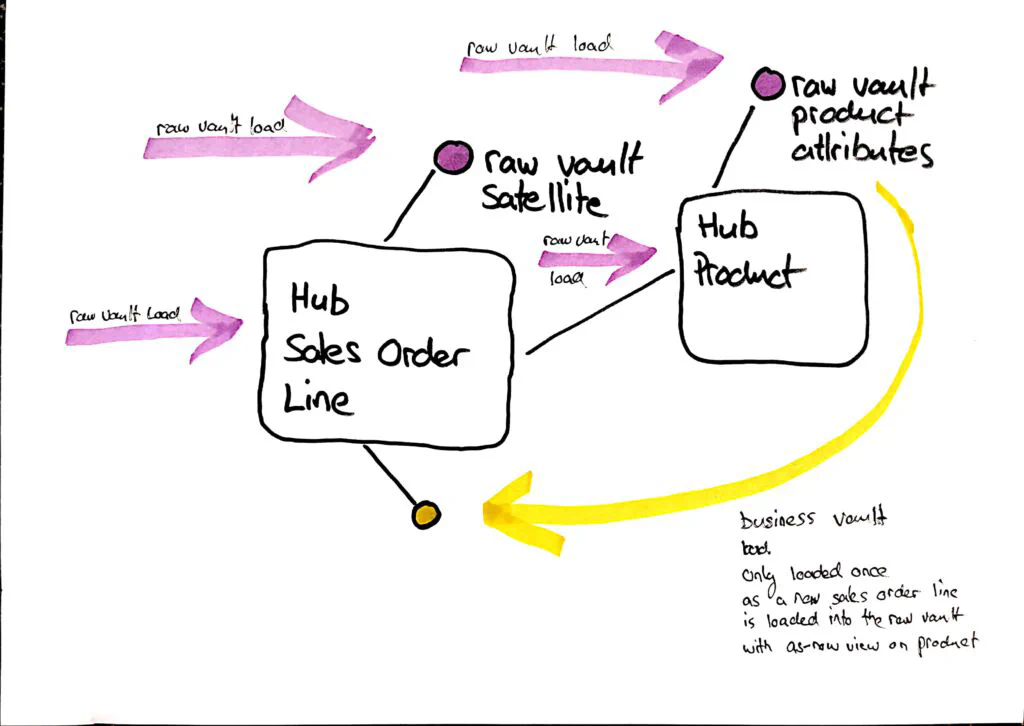
If we now output the sales order, we can now also issue the Business Vault attribute on this grain of the transaction. Every user understands that this attribute is something at the time of the transaction. You don’t have to do any look-ups when exporting to the reports, and you no longer have multiple dimensions for the same object.

Short summary
With these three simplifications / strategies,
-
storing 2d just as an attribute in the satellite
-
inclusion of the 1d time in the hub key
-
instantiation of attributes on the transaction
I claim we can cover most of the requirements for a historicized output in most industries. In a third article, I will discuss the cases where this is not sufficient and what are the technical solutions for such requirements. Footnotes *1 The example with Basel as the place of residence is completely invented - of course, I would never consider living in Basel, just as no “Basler” would consider living in Zurich as far as this can be prevented. *2 Again, special reports are excluded: if, for example, I want to evaluate the quality of data entry in the source system, such name changes may, of course, be relevant. *3 Can also be used analogously for 3d history if it is used as an approximation for 1d. *4 The problem that several MA satellites cannot be connected without special rules, because otherwise a cross product is created, I do not deal with in detail, because with the special subtype of the bi-temporal satellite you can find an automated pattern to cross out the entries correctly, if you capture the time/date fields in the metadata. *5: you can also map the whole thing differently by linking only the as-then (as-of-then) dimension in the fact and then making a self-link on the dimension itself for the as-now (as-of-now) values. This is not supported by certain reporting tools like QlikView etc. But the main reason why I didn’t list this variant is that it doesn’t make the report simpler in my opinion, but more complicated. *7 I took this expression from some ETH professors in Zurich who write mathematical formulas on the two-room wide blackboard and explain them at the end, just because it is deterministic, it is trivial *8 here I like to be instructed if there is a more suitable / clearer expression
See Datavault Builder in action
20-minute demo. Honest answers on whether it fits your team.
Book a Free Demo